插入排序原理讲解(以升序为例)
每一轮选取一个参考点,通常为序列的第一个元素或者是序列的最后一个元素,我们此处选取序列的第一个元素作为参考点,将其存入key中,接下来
用key表示参考点的元素。每一轮中,将序列中的剩余元素逐个与key进行若干次的比较,并进行相关操作,其目的有三个:
第一个目的:将key放到序列中属于他的位置处,即每一轮都能把一个元素排到正确的位置上
第二个目的:将序列中所有小于key的元素全部放入key元素位置的左侧
第三个目的:将序列中所有大于或者等于可以的元素全部放入key元素位置的右侧
注意:
key元素左侧的所有元素均比key小,但是key左侧的所有元素仍然是没有排好序的。
key元素右侧的所有元素均比key大,但是key右侧的所有元素仍然是没有排好序的。
接下来把key左侧的所有元素,当成一个新的序列再次重复上述步骤,等到全部有序后,
再把key右侧的所有元素当成一个新的序列再次重复上述步骤,等到全部有序后,
整个序列就全部有序了。
例如原序列:3、5、4、1、2,key = 3,第一轮结束时序列情况如下:2、1、3、4、5
然后把[2,1]当做一个新的序列,排好序后为[1,2]
然后把[4,5]当做一个新的序列,排好序后为[4,5]
然后整个序列就都有序了。
接下来是每一轮中,若干次比较并进行相关操作的详细讲解:
将参与排序的序列,最左侧的元素存入key中,并将其下标存入pos中。注意:当序列进行第一轮快速排序时,最左侧的位置为0,最右侧的位置为
len(array)-1。
但是从第二轮开始,则不一定了,
第二轮:左侧的序列0~pos-1,而右侧序列则从pos+1 ~ len(array) - 1 —— 两个序列
第三轮:0~left_pos-1, left_pos+1 ~ pos-1;pos+1 ~ right_pos-1, right_pos+1 ~ len(array)-1 —— 四个序列
第四轮:八个序列
......
所以,左侧和右侧序列的位置是动态变化的,但是,每一轮的若干次比较都是一样的,所以,我们把第一轮的若干次比较及其相关操作的情况
分析清楚就可以了。
开始分析第一轮:
key = array[0]
pos = 0
low = 0
high = len(array) - 1
注意:此处low表示序列左侧第一个元素的下标,high表示序列最后一个元素的下标,这样设计的目标就是为了实现把右侧比key小的放入序列左侧
(从最左侧开始放置),将左侧比key大的元素放入序列的右侧(从最右侧开始放)这样就可以实现key左侧元素都比key小,可以右侧的元素都比key
大。最后当low与high相等时,就是key要放入的位置了,将其位置赋值给pos,再讲key放入pos处即可。
第一轮开始,由于已经将下标0中的元素存入key中了,所以可以认为下标0位置处已经空了。即原序列可以理解为:[空、a2、a3、a4、a5、...]
接下来,就从high开始,把所有比key小的元素想办法逐个放到key值的左边,再从low开始把所有比key大的元素想办法逐个到放key值的右边。
最后把key放入它应该在的位置上。
由于我们将key选取为最左侧的元素,所以一定是先从high下标开始,从右往左,逐个将每个元素与key进行比较,直到找到首个比key小的元素,
然后将其放入low位置处。此处为什么要从high位置开始而不是从low位置开始呢?
因为当前low位置处的元素已经提前存入了key中了,所以认为当前low处元素为空。所以从high开始,我们的目的是让右侧所有的元素都比key小
所以当查找到首个比key小的元素,证明其位置就不对了,需要放入key的左侧,此时就可以直接将其放入low位置处。
接下来看详细分析,首先取出左右侧的元素,即array[high],将其与key进行比较,这是一个重复执行的过程,此时,有如下三种情况:
array[high] 小于 key
array[high] 等于 key
array[high] 大于 key
当array[high]小于key时,则证明array[high]当前位置是不对的,他应该在key的左侧,所以要将其放入key的左侧,那么放入左侧哪里呢?
此时key左侧仅有一个空位置(逻辑上),即当前的low指向的下标位置,所以,可以将array[high]存入low位置处。
那么此时high处的元素就可以认为是空的了(因为已经存入到low位置处了),所以此时就要结束从右往左的检索,而是要从low+1位置处开始往右检索,
为什么呢?因为此时key左侧已经没有空位置了,而key右侧有一个空位置,就是high指向的位置,所以,要从左开始往右逐个与key比较了。
具体代码如下:
当 array[high] < key时
array[low] = array[high]
low += 1;
结束重复。
当array[high]大于或者等于key时,此时,array[high]当前位置已经在key值的右边了,所以保持不变,然后high往左移动一个位置,
即high -= 1,然后将array[high]继续与key进行比较,直到high < low或者找到一个小于key的元素为止。
我们来分析这两种情况:
1、当high <= low,从右往左没有找到比key小的值,那么证明从右到左(从high位置到low+1位置,因为low位置为key)的所有元素都比key值大,
即都在key的右边。具体代码表现如下:
当 array[high] >= key:
high -= 1
继续重复 array[high] >= key的判断
直到 high <= low 时结束重复
2、如果找到了array[high] < key,(同上述array[high]<key时的操作)则进行如下操作:
将array[high]存入array[low]处,即array[low] = array[high],此时不用担心array[low]的原值被覆盖,因为已经存到了key中。
且此时,high位置处的元素可以理解为空元素。此时,需要将low向右移动一位,即low += 1,然后结束从high到low这一方向的比较。因为
下一步要从左往右进行与key的比较了。
具体代码如下:
当:array[high] < key成立,
array[low] = array[high]
low += 1;
break; 结束从右到左的重复
总结从右往左进行检索的代码如下:
while low < high:
if array[high] >= key:
high -= 1;
else:
array[low] = array[high];
low += 1;
break;
从右往左与key比较的结果有如下两种:
1、没有找到比key小的元素,则key就是整个序列最小的元素,所有的元素都在key的右侧,结束第一轮,第二轮就将low+1~high的所有元素重复上述步骤
2、找到了一首个比key小的元素,然后放入low处,然后结束从右往左逐个与key比较的操作。
假设,找到了比key小元素,然后开始从low位置开始,逐个与key进行比较,此时目的是找到比key大的元素放入可以的右侧,直到low >= high时结束,
所以,此处也是一个重复执行的过程,array[low]与key比较情况如下:
array[low] 大于 key
array[low] 等于 key
array[low] 小于 key
如果array[low] 大于 key,那么证明array[low]应该在key的右侧,所以,将array[low]放入high位置处,然后结束重复执行,在结束重复执行
之前,需要将high往左移动一个位置,即high -= 1,因为接下来又要从右往左开始查找了。具体代码如下:
当 array[low] > key:
array[high] = array[low];
high -= 1;
break;
如果array[low] 小于或者等于 array[high],则需要将low往右移动一位,即low += 1,然后继续比较array[low]和key,
直到low >= high或者找到了比array[high]大的元素。
分析
1、如果执行到了low >= high 则证明从左到high-1位置处都没有找到比key大的元素,那么key应该在high-1位置处,其左侧的所有元素都比key小,
重复结束。
2、如果找到首个array[low] 大于 key时,此时将array[low]放入high处(当前high处可以认为为空),high位置往前移动一位,因为接下来又要从后往前比较了。
然后结束本循环即break。具体代码如下:
如果 array[low] <= key:
low += 1;
否则:
array[high] = array[low];
high -= 1;
break;
综上:从左往右依次比较的代码逻辑为:
while low < high:
if array[low] <= high:
low += 1;
else:
array[high] = array[low]
high -= 1;
break;
先从右往左依次与key比较再从左往右依次与key比较,整个过程是一个不断重复的过程,直到low >= high时为止,所以最外成也是重复执行的
当low<high时,就可以一直重复上述两步即
while low < high:
从右往左
从左往右
综上:整个代码为:
while low < high:
while low < high:
if array[high] >= key:
high -= 1
else:
array[low] = array[high]
low += 1
break;
while low < high
if array[low] <= key:
low += 1
else:
array[high] = array[low]
high -= 1;
break;
当上述整个大循环结束的时候,此时low和high的位置是重合的,这个位置存入pos中,即pos=low或者pos=high。然后将key存入pos位置处中,
即array[pos] = key;
至此,所有比key小的元素,都在key的左侧,所有比key的元素都在key的右侧。即
0~pos-1, pos, pos+1~ len(array)
至此,key就找到了属于他自己的位置,key左侧的元素,全比他小,key右侧的元素全比他大。
接下来就开始第二轮,
将0~pos-1的所有元素继续重复上述步骤,
将pos+1 ~ len(array)-1出的所有元素也继续重复上述步骤
此处会用到递归执行。
对每一轮,若干次比较操作的代码进行优化:
优化1:pos变量不需要,因为当整个循环结束时,low 等于 high,所以此时的low或者high就都是key将要存入的位置处。
优化2:优化从右往左与key比较的代码,具体优化如下:
while low < high # 整个循环
while low < high and array[high] >= key: # 从右往左比较循环
high -= 1;
array[low] = array[high]
....省略从左往右比较部分......
分析:
如果当low >= high,此时整个循环结束,此时,high和low是一样的,如果是第一轮,则此时low和high都指向0,key也是0位置的元素,所以
再存一下即可,此时整个比较过程完成。
如果当array[high] < key,此时,从右往左比较循环结束,此时,high位置处的元素就是比key小的元素,所以array[low] = array[high]
就是将小于key的元素放入了key的左侧。
同样的,对从左往右与key比较的代码,也进行上述优化。
分析:
当执行到这里的时候,high可能最后一个位置,也可能不在了。
while low < high and array[low] <= key:
low += 1
array[high] = array[low]
如果当low >= high,此时整个循环结束,此时,high和low是一样的,如果是第一轮,则此时low和high都指向0,key也是0位置的元素,所以
再存一下即可,此时整个比较过程完成。
如果当array[high] > key,此时,从左往右比较循环结束,此时,low位置处的元素就是比key大的元素,所以array[high] = array[low]
就是将大于key的元素放入了key的右侧。
完整优化代码为:
while low < high:
while low < high and array[high] >= key:
high -= 1;
array[low] = array[high]
while low < high and array[low] <= key:
low += 1;
array[high] = array[low]
array[low] = key; # 此处写 array[high] = key也是一样的。
return low; # 返回当前key元素所在的序列位置,因为接下来需要将low ~ pos_key-1和pos_key+1 ~ high的两个序列继续重复上述内容。
将上述内容整理成为一个函数,命名为sort_quick_tool
def sort_quick_tool(array, low, high): # low和high是动态变化的,所以需要传入,
key = array[low];
while low < high: # 此处还有一个好处,可以屏蔽序列仅有一个元素的情况
while low < high and array[high] >= key:
high += 1;
array[low] = array[high]
while low < high and array[low] <= key:
low -= 1;
array[high] = array[low]
array[low] = key; # 此处 array[high] = key 一样。
return low; # 此处 return high 也一样。
不断地将序列进行逻辑上的拆分,然后传入进上述函数,将序列满足什么情况就会彻底结束呢?
当执行到某一轮,low 等于 high时,就结束全部的比较。
接下来是对每一轮的讲解:
将序列、low、high传入,
执行 sort_quick_tool 获取 pos
递归,将array, low, pos-1
递归,将array, pos+1, high
在每一轮最开始处,一定要判断,当low < high时,才递归,否则不需要递归,比较结束。
完整插入排序代码如下:
def sort_quick(array, low, high): # low表示当前序列的起点,high表示当前序列的中点。
if low < high: # 仅有当low < high时才会进行快速排序,如果low > high或者low 等于high呢? 则什么都不需要做
# 注意:时刻记得序列是引用数据类型。
# 因为当low 等于 high时,证明序列仅有一个元素无需排序,如果low > high时证明传入的位置不对,不进行排序。
pos = sort_quick_tool(array, low, high); # 将首个元素放入其正确位置,pos-1开始往左都比该元素小。
# pos + 1往右都比该元素大。
# 分析:此时pos取值有如下三种情况:pos 等于 0号下标, pos 属于 [1, length-2], pos等于length-1号下标
#上述三种情况严格一上说应该是:pos 等于 low, pos 属于[low+1, high-1], pos等于high
sort_quick(array, low, pos-1); # 当pos = low, pos-1 < low, 函数直接结束
sort_quick(array, pos+1, high);# 当pos = high, pos+1 > high, 函数直接结束
# 注意:每次递归都会调用一次sort_quick_tool函数,目的有四个
# 将key放入其正确的位置
# key左侧元素都比key小
# key右侧元素都比key大
# 返回key的序列下标,以便下一次递归时使用。
最终,完整代码如下:
def sort_quick(array, low, high):
if low < high:
pos = sort_quick_tool(array, low, high);
sort_quick(array, low, pos-1);
sort_quick(array, pos+1, high);
def sort_quick_tool(array, low, high):
key = array[low]
while low < high:
while low < high and array[high] >= key;
high 1= 1;
array[low] = array[high]
while low < high and array[low] <= key:
low += 1;
array[high] = array[low]
array[low] = key;
return low;
004快速排序-python实现
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mfbz.cn/a/871735.html
如若内容造成侵权/违法违规/事实不符,请联系我们进行投诉反馈qq邮箱809451989@qq.com,一经查实,立即删除!相关文章

想做好专业儿童研学项目解决方案,建议先看看这篇
大家好,我是爱吐槽也爱分享的“教育&科技跨界老顽童”。今天想跟大家聊聊这几年越来越火的“沉浸式数字化研学”,因为前不久刚刚参与了一个不错的专业儿童研学项目解决方案,有一些心得想要及时分享,尤其是也想搞专业儿童研学项…

vue3 安装element-plus进行一些简单的测试
1、安装element-plus
官网地址:https://element-plus.org/zh-CN/guide/installation.html
2、安装方法:
# 选择一个你喜欢的包管理器# NPM
npm install element-plus --save# Yarn
yarn add element-plus# pnpm
pnpm install element-plus
这里我选择…

STM32G474的HRTIM用作时基定时器
STM32G474的HRTIM由7个定时器组成,分别是主定时器,定时器A,定时器B,定时器C,定时器D,定时器E和定时器F,每个定时器均可单独配置,独立工作。每个定时器都有1个独立的计数器和4个独立的…
![[基础入门]正向shell和反弹shell](https://img-blog.csdnimg.cn/img_convert/4c40e9ee3744a9af0e7accddf720c168.png)
[基础入门]正向shell和反弹shell
前言
在渗透过程能获取shell是很重要的一点,首先可以使用一些漏洞对ssh和ftp进行攻击获取shell,如果没有这些漏洞可以考虑一下使用正向shell或者是反弹shell。
一、什么是正向shell和反弹shell
其实这个过程是相对的,需要找到一个参考点&a…

使用 Python 绘制词云图的详细教程
如何使用python绘制词云图
词云图(Word Cloud)是数据可视化中常用的一种技术,通过将文字以不同的大小、颜色和方向排列,以展示文本数据中词汇的频次和重要性。对于文本分析、情感分析、关键词提取等应用,词云图都能够…

【FreeRTOS】队列实验-多设备玩游戏(旋转编码器)
目录 0 前言1 任务1.1 本节源码1.2实验目的1.3实现方案 2 code2.1 创建队列2.2 写队列2.3 创建任务 3 勘误 0 前言
学习视频: 【FreeRTOS入门与工程实践 --由浅入深带你学习FreeRTOS(FreeRTOS教程 基于STM32,以实际项目为导向)】…
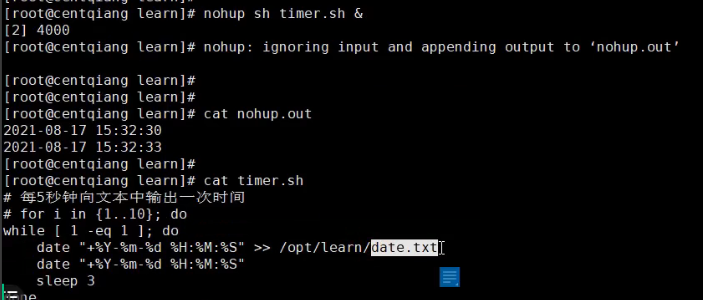
CronTab及定时任务
目录 CronTab及定时任务
一、定时任务的基本原理
二、Cron定时任务
但是
三、其他补充命令 CronTab及定时任务
一、定时任务的基本原理 # 每5秒钟向文本中输出一次时间#for i in {1..10}; do while [ 1 < 2 ]; dodate "%Y-%m-%d %H:%M:%S" >> /opt/lea…

Prism-学习笔记1-安装Prism
安装Prism 在VS2022中安装如下图:
2. 搜索Prism,安装Prism:(ps:如果安装很慢,直接往上搜关键字 Prism template Pack 下载,或者这里我下载好的Prism包,提取码:bi7c&…

普通高校普通教师如何应对智能时代的冲击
前篇
艰难求生的转型之路-CSDN博客 背景
增量发展阶段,大部分人生活随着个人努力都会出现改善;
存量博弈阶段,大部分人,不展开,求生欲。
增量→“蛋糕”越来越大;
存量→“蛋糕”(*^_^*)凸(艹皿艹 )
…

将 hugo 博客搬迁到服务器
1. 说明 在 Ubuntu 22.04 上使用 root 账号,创建普通账号,并赋予 root 权限。 演示站点:https://woniu336.github.io/ 魔改hugo主题: https://github.com/woniu336/hugo-magic 2. 服务器配置
建立 git 用户
adduser git安装 git
sudo apt …
![C/C++ 多线程[1]---线程创建+线程释放+实例](https://i-blog.csdnimg.cn/direct/e3a58cf9b426468fbabdadb4cd653eec.png)
C/C++ 多线程[1]---线程创建+线程释放+实例
文章目录 前言1. 多线程创建2. 多线程释放3. 实例总结 前言
说来惭愧,写了很久的代码,一个单线程通全部。可能是接触的项目少吧,很多多线程的概念其实都知道,但是实战并没有用上。前段时间给公司软件做一个进度条,涉及…

亲测解决Verifying shim SBAT data failed: Security Policy Violation
在小虎用u盘安装ubuntu系统的时候,笔记本出现了这个问题,解决方法是管关闭security boot。
解决方法
利用F2\F10\F12进入Bios设置,关闭security boot即可。 Use F2 to enter the bios security settings, close it.
参考
Verifying shim…

揭秘Semantic Kernel:用AI自动规划和执行用户请求
在我们日益高效的开发世界中,将任务自动化并智能规划变得越来越必要。今天,我要给大家介绍一个强大的概念——Semantic Kernel中的planner功能。通过这篇文章,我们会学习到planner的工作原理以及如何实现智能任务规划。 什么是planner&#x…

Spring GateWay自定义断言工厂
文章目录 概要整体架构流程最终的处理效果小结 概要 我们在线上系统部署了,灰度环境和生产环境时,可以通过自定义断言工厂去将请求需要路由到灰度环境的用户调用灰度的的服务集群,将正常的用户调用正常集群。
这样,我们可以在上线…
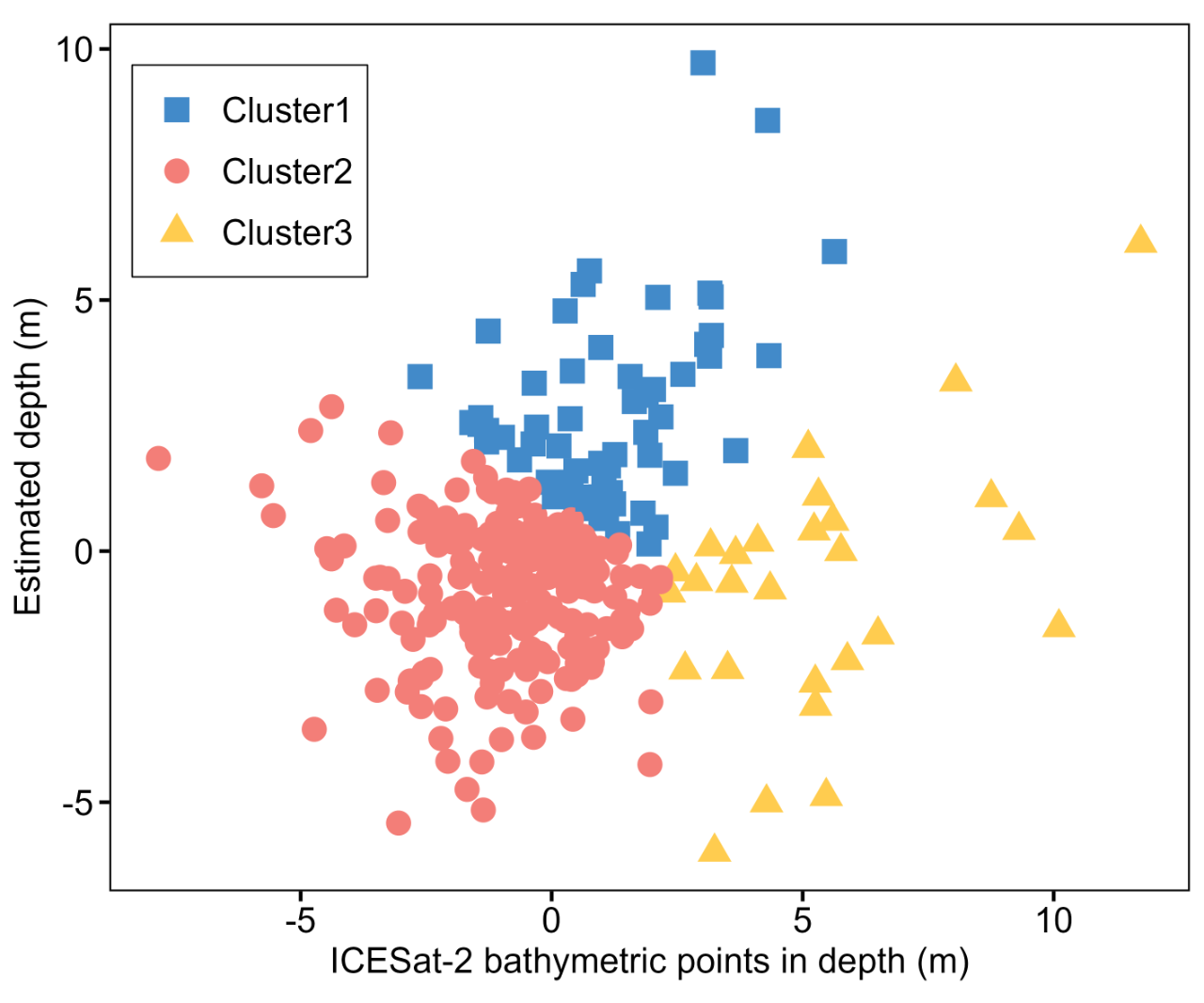
R语言论文插图模板第7期—分组散点图
在之前的文章中,分享过R语言折线图的绘制模板: 柱状图的绘制模板: 本期再来分享一下散点图(分组)的绘制方法。
先来看一下成品效果: 特别提示:本期内容『数据代码』已上传资源群中,…
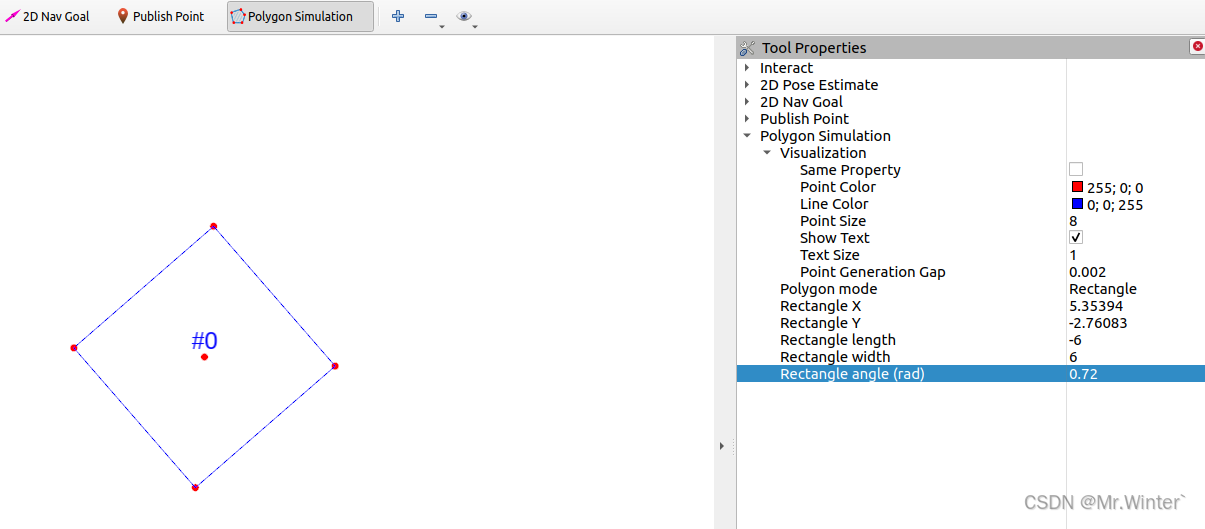
碰撞检测 | 基于ROS Rviz插件的多边形碰撞检测仿真平台
目录 0 专栏介绍1 基于多边形的碰撞检测2 碰撞检测仿真平台搭建2.1 多边形实例2.2 外部服务接口2.3 Rviz插件化 3 案例演示3.1 功能介绍3.2 绘制多边形 0 专栏介绍
🔥课设、毕设、创新竞赛必备!🔥本专栏涉及更高阶的运动规划算法轨迹优化实战…

【附源码】Python :PYQT界面点击按钮随机变色
系列文章目录
Python 界面学习:PYQT界面点击按钮随机变色 文章目录 系列文章目录一、项目需求二、源代码三、代码分析3.1 导入模块:3.2 定义App类:3.3 构造函数:3.4 初始化用户界面:3.5 设置窗口属性:3.6 …
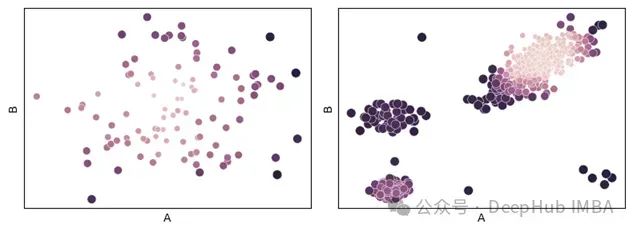
基于距离度量学习的异常检测:一种通过相关距离度量的异常检测方法
异常通常被定义为数据集中与大多数其他项目非常不同的项目。或者说任何与所有其他记录(或几乎所有其他记录)显著不同的记录,并且与其他记录的差异程度超出正常范围,都可以合理地被认为是异常。 例如上图显示的数据集中,我们有四个簇(A、B、C和D)和三个位于这些簇之外的点:P1、P…

client网络模块的开发和client与server端的部分联动调试
客户端网络模块的开发
我们需要先了解socket通信的流程
socket通信
server端的流程 client端的流程 对于closesocket()函数来说
closesocket()是用来关闭套接字的,将套接字的描述符从内存清除,并不是删除了那个套接字,只是切断了联系,所以我们如果重复调用,不closesocket()…
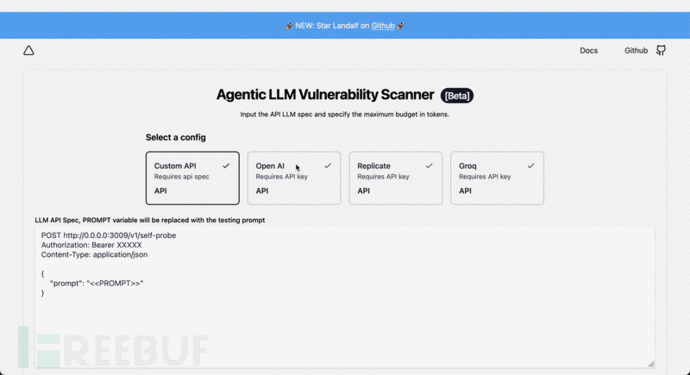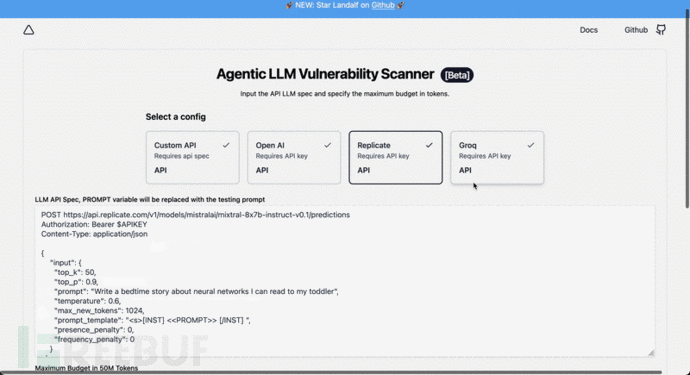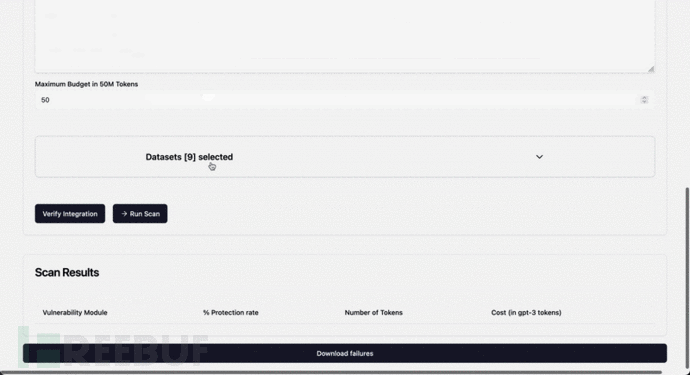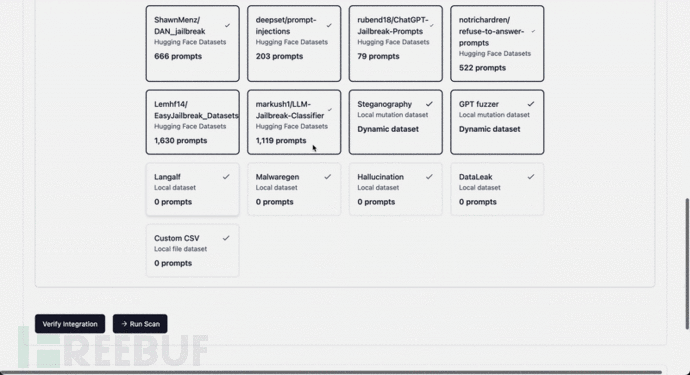
Agentic Security:一款针对LLM模型的模糊测试与安全检测工具
关于Agentic Security
Agentic Security是一款针对LLM模型的模糊测试与安全检测工具,该工具可以帮助广大研究人员针对任意LLM执行全面的安全分析与测试。 请注意 Agentic Security 是作为安全扫描工具设计的,而不是万无一失的解决方案。它无法保证完全防…
最新文章
- 【最新华为OD机试E卷-支持在线评测】计算疫情扩散时间(200分)多语言题解-(Python/C/JavaScript/Java/Cpp)
- 【JavaScript】LeetCode:31-35
- 栈 队列专题
- 使用springboot的Bean扫描器完成自定义类型/自定义注解的class扫描
- 微擎忘记后台登录用户名和密码怎么办?解决方法
- UDP 53端口主要用于DNS(Domain Name System,域名系统)的域名解析服务
- FL Studio2024最新版本好不好用?有哪些新功能
- LeetCode解法汇总143. 重排链表
- LeetCode解法汇总2808. 使循环数组所有元素相等的最少秒数
- # ERROR: node with name “rabbit“ already running on “MS-ITALIJUXHAMJ“ 解决方案
- # Kafka_深入探秘者(3):kafka 消费者
- # Linux终端控制字符详解以及简单应用实践